In machine learning, entropy is one of the most important things and understanding the different loss functions within entropy is crucial. It can help you achieve optimal performance in various tasks. Within the loss functions of entropy, there are binary bross entropy and categorical cross entropy. These are two common loss functions that people who deal with machine learning encounter with and they look quite similar from the outside. However, when you compare binary cross entropy vs categorical cross entropy, you see that they are not the same.
Both measure the dissimilarity between predicted and actual class labels. But they have distinct applications and functionalities.
In this blog post, we will compare Binary Cross Entropy vs Categorical Cross Entropy and explain what they are. We will examine the definitions, applications, and calculations of Binary Cross Entropy and Categorical Cross Entropy.
Understanding Entropy in Machine Learning
Entropy is a concept in information theory and machine learning that measures the uncertainty or randomness in a system. It provides a quantitative measure of the amount of information in a dataset. It is crucial in various machine learning algorithms, including classification tasks.
We generally use entropy to check the impurity or disorder of a system’s class labels in machine learning. The higher the entropy, the more uncertain or diverse the class labels are. In comparison, lower entropy indicates a more homogeneous distribution of class labels.
Consider a binary classification problem as an example. Suppose we have a dataset with two classes. Positive and negative. The goal is to predict the correct class for each data point.
With this formula, we can calculate entropy, denoted as H.
H = -p(positive) log2(p(positive)) – p(negative) log2(p(negative))
Here, p(positive) represents the probability of a data point being positiv. P(negative) represents the probability of a data point being negative.
If the dataset is perfectly balanced, with equal positive and negative samples, the entropy would be at its maximum value of 1. This indicates maximum uncertainty, as it is equally likely for a data point to belong to either class. On the other hand, if the dataset contains only one class, the entropy would be 0, indicating no uncertainty as all data points belong to the same class.
Machine learning aims to minimize entropy by finding the best split or decision boundary that separates the classes effectively. This is where loss functions like Binary Cross Entropy and Categorical Cross Entropy come into play. They quantify the dissimilarity between predicted and actual class labels and guide the learning process.
What is Binary Cross Entropy?
Binary Cross Entropy, also known as Log Loss, is a measure of dissimilarity. It measures the dissimilarity between the predicted probabilities and a dataset’s true binary class labels. Binary Cross Entropy is a popular loss function that we use in binary classification problems. These tasks involve separating data points into two distinct classes.
It quantifies the error between the predicted probabilities and the actual binary labels, providing a single scalar value that represents the performance of a binary classification model.
The Binary Cross Entropy loss function comes from information theory. Given the predicted probabilities, it calculates the average number of bits needed to represent the true class labels. The lower the Binary Cross Entropy value, the better the model’s predictions align with the true labels.
When to Use Binary Cross Entropy?
We primarily use Binary Cross Entropy in binary classification tasks. In these tasks, the goal is to classify data points into one of two classes. It is commonly employed in various domains, including spam detection, fraud detection, sentiment analysis, and disease diagnosis.
Functionality and Calculation of Binary Cross Entropy
We calculate the loss function of The Binary Cross Entropy with the following formula.
Binary Cross Entropy = – (y * log(p) + (1 – y) * log(1 – p))
Where.
- y represents the true binary class label (0 or 1)
- p represents the predicted probability of the positive class (between 0 and 1)
The formula consists of two terms. one for the positive class (y = 1) and one for the negative class (y = 0). It penalizes the model more when the predicted probability deviates from the true label. As the predicted probability approaches the true label (0 or 1), the Binary Cross Entropy loss approaches zero.
The goal is to minimize the Binary Cross Entropy loss during training by adjusting the model’s parameters through techniques like gradient descent. Binary Cross Entropy is a versatile loss function that we frequently use in binary classification problems.
What is Categorical Cross Entropy?
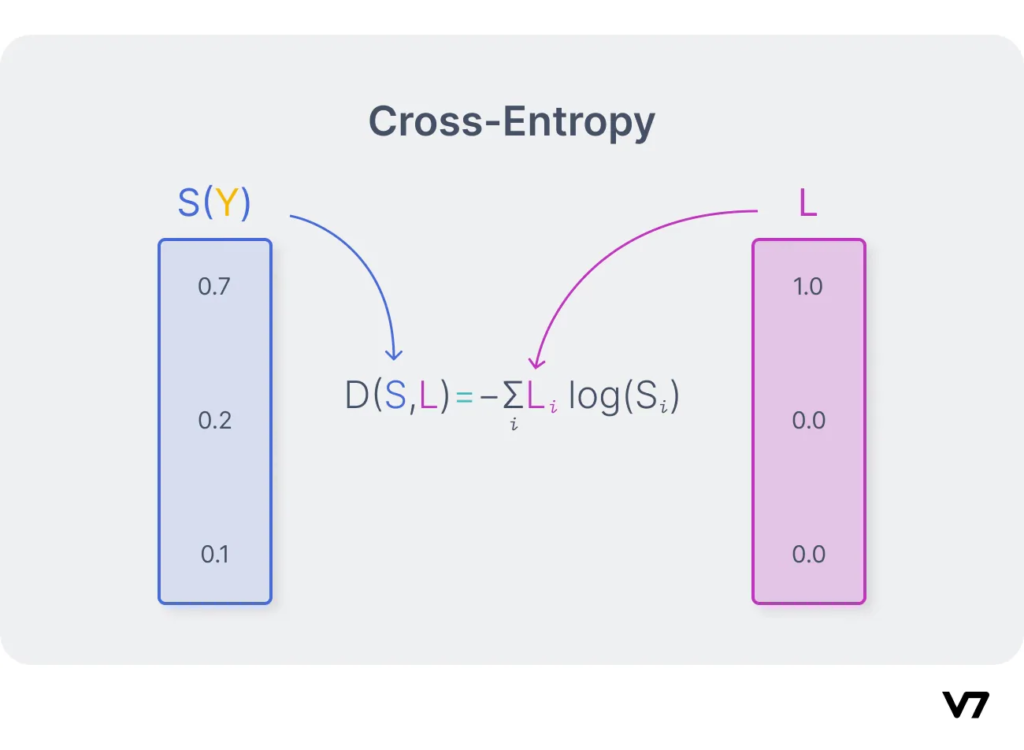
Categorical Cross Entropy is a measure of dissimilarity of the predicted class probabilities and the true class labels of a multi-class classification problem. Categorical Cross Entropy is a loss function commonly used in multi-class classification tasks, where the objective is to classify data points into more than two distinct classes.
It quantifies the error between the predicted probabilities and the actual class labels, providing a single scalar value that represents the performance of a multi-class classification model.
Unlike Binary Cross Entropy, which is designed for binary classification, Categorical Cross Entropy considers multiple classes. It calculates the average loss across all classes. It provides a more comprehensive evaluation of the model’s performance in distinguishing between different classes.
When to Use Categorical Cross Entropy?
Categorical Cross Entropy is specifically designed for multi-class classification problems, where the task involves assigning data points to one of several classes. It is widely used in various applications, including image recognition, natural language processing, and document classification.
Functionality and Calculation of Categorical Cross Entropy
The Categorical Cross Entropy loss function formula is this.
Categorical Cross Entropy = – Σ(y * log(p))
Where.
- y represents the true class label vector (a one-hot encoded vector)
- p represents the predicted class probabilities vector
The formula sums up the element-wise multiplication of the true class label vector and the logarithm of the predicted class probabilities vector. It penalizes the model more when the predicted probabilities deviate from the true labels across all classes.
The goal is to minimize the Categorical Cross Entropy loss during the training process by adjusting the model’s parameters through techniques like gradient descent.
Binary Cross Entropy vs Categorical Cross Entropy
Now that we have a broader understanding of these two terms, let’s compare binary cross entropy and categorical cross entropy. Understanding the differences will help you determine which loss function to use in different scenarios.
Similarities Between Binary Cross Entropy and Categorical Cross Entropy
- Measure of Dissimilarity. Both loss functions quantify the dissimilarity between predicted probabilities and true labels, providing a measure of how well the specific model’s predictions align with the actual class labels.
- Loss Minimization. The objective for both loss functions is to minimize their respective values. By minimizing the loss, the model aims to improve its performance in classifying the data points correctly.
- Logarithmic Nature. Both Binary Cross Entropy and Categorical Cross Entropy involve the use of logarithmic functions in their calculation. This logarithmic nature helps penalize larger deviations between predicted probabilities and true labels.
Differences Between Binary Cross Entropy and Categorical Cross Entropy
- Number of Classes. The primary difference lies in the number of classes they are designed to handle. Binary Cross Entropy is used for binary classification tasks, where there are only two classes. In contrast, Categorical Cross Entropy is specifically designed for multi-class classification problems where there are more than two classes.
- Output Format. Binary Cross Entropy produces a single scalar value representing the loss for each data point. At the same time, Categorical Cross Entropy calculates the average loss across all classes, resulting in a single scalar value for the entire dataset.
- Label Representation. Binary Cross Entropy uses a single binary value (0 or 1) to represent the true class label, indicating whether the data point belongs to the positive or negative class. On the other hand, Categorical Cross Entropy requires the true class label to be represented as a one-hot encoded vector, where only one element is 1, indicating the class membership.
- Calculation Formula. Binary Cross Entropy and Categorical Cross Entropy employ different formulas for their calculations. Binary Cross Entropy considers the predicted probability for the positive class, while Categorical Cross Entropy compares the predicted class probabilities across all classes.
Choosing Between Binary Cross Entropy and Categorical Cross Entropy
Choosing the appropriate loss function depends on the nature of your classification problem. If you have a binary classification task where there are only two classes, Binary Cross Entropy is the suitable choice. On the other hand, if you are dealing with a multi-class classification problem involving more than two classes, Categorical Cross Entropy is the preferred option.
Real World Applications and Examples of Binary and Categorical Cross Entropy
Both binary cross entropy and categorical cross entropy have real-world applications. This means we use both of these things in our world to achieve things that allow us to. They have different use cases because of the differences in their nature.
Binary Cross Entropy Applications and Examples
- Spam Detection. Binary Cross Entropy is commonly used in email spam detection systems. By training a model with Binary Cross Entropy loss, it can learn to distinguish between spam and non-spam emails based on various features, such as subject lines, message content, and sender information.
- Fraud Detection. Binary Cross Entropy is applicable in fraud detection systems, where the goal is to identify fraudulent transactions. By training a model using Binary Cross Entropy loss, it can learn to classify transactions as either fraudulent or non-fraudulent based on features like transaction amount, location, and user behavior patterns.
- Sentiment Analysis. Binary Cross Entropy is useful in sentiment analysis tasks, where the objective is to determine the sentiment (positive or negative) of a text. By training a model with Binary Cross Entropy loss, you can teach it to classify text snippets, such as customer reviews or social media posts, based on their sentiment.
Categorical Cross Entropy Applications and Examples
- Image Recognition. Categorical Cross Entropy is widely used in image recognition tasks, where the objective is to classify images into different categories. When you train a convolutional neural network (CNN) with Categorical Cross Entropy loss, it can learn to recognize objects, scenes, or people in images.
- Natural Language Processing. Things like text classification, sentiment analysis, and language translation are all part of where categorical cross entropy comes in. By training models with Categorical Cross Entropy loss, they can learn to classify text documents or generate accurate translations.
- Document Classification. Categorical Cross Entropy is useful in document classification tasks, where the goal is to categorize documents into different topics or classes. By training a model with Categorical Cross Entropy loss, it can learn to classify documents based on their content, enabling efficient document organization and retrieval.
Conclusion
In conclusion, having a clear understanding of “Binary Cross Entropy vs Categorical Cross Entropy” is important for practitioners in the field of machine learning and those interested in the area. These two loss functions play distinct roles in classification tasks, addressing the nuances of binary and multi-class scenarios with precision.
The comparison between these loss functions reveals their shared goal of minimizing dissimilarity between predicted and true labels, while their differences lie in the number of classes, output format, label representation, and calculation formulas.
FAQ
What is the difference between binary cross-entropy and entropy?
Binary cross-entropy measures the difference between predicted and actual outcomes in a two-class classification scenario. Entropy is a broader concept used in information theory to quantify uncertainty or disorder in data.
While binary cross-entropy is specific to binary classification, entropy has broader applications in various fields. Entropy can be applied to different scenarios, not just classification, making it a more general concept.
Why binary cross-entropy for classification?
Binary cross-entropy is suitable for classification because it efficiently models the probability distribution for two-class outcomes, aiding model training.
What is categorical cross-entropy?
Categorical cross-entropy is a loss function for multi-class classification, measuring the difference between predicted and actual class probabilities.